深入理解Geth与Ethereum的存储结构
| Tags | 数据存储 |
|---|
数据结构概览
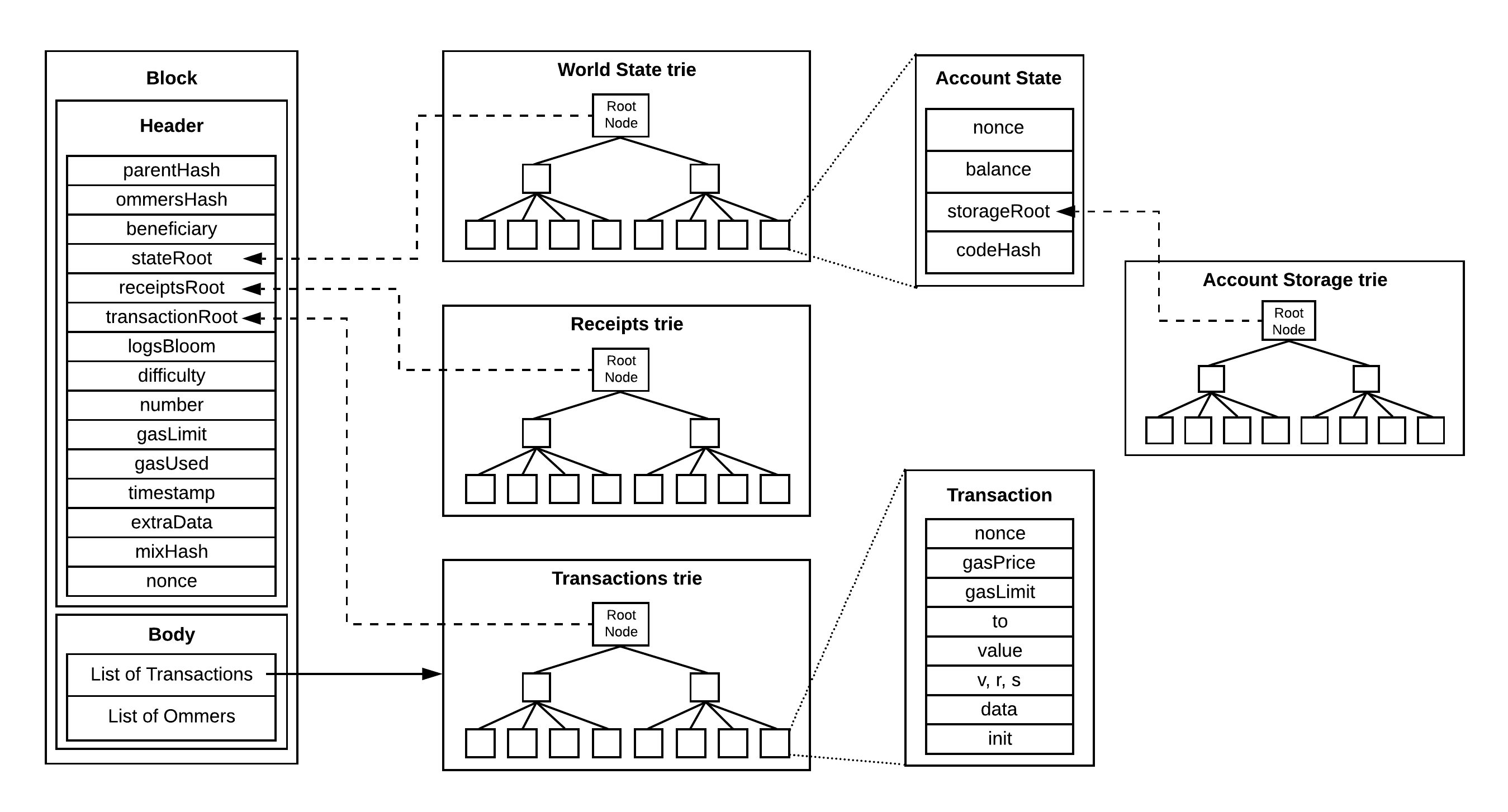
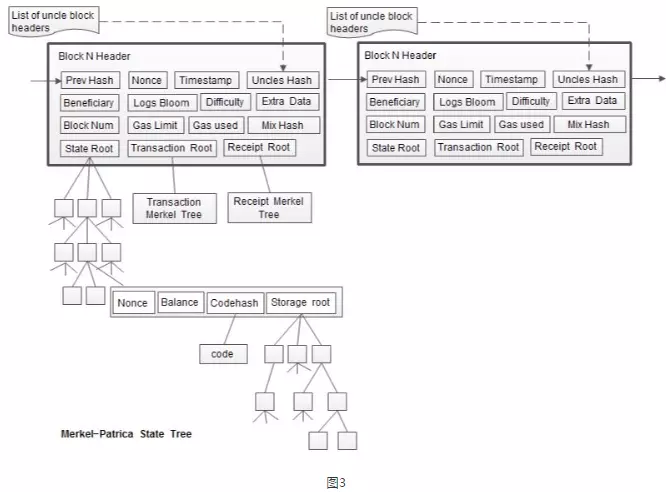
众所周知,以太坊里面有4棵树,分别是:
- 世界状态树(World State Trie)
- 交易树 (Transactions Trie)
- 收据树(Receipts Trie)
- 账户存储树(Account Storage Trie)
当我们启动geth,到底同步了哪些东西?
geth在默认提供的是fast同步模式,我们在完成同步之后……
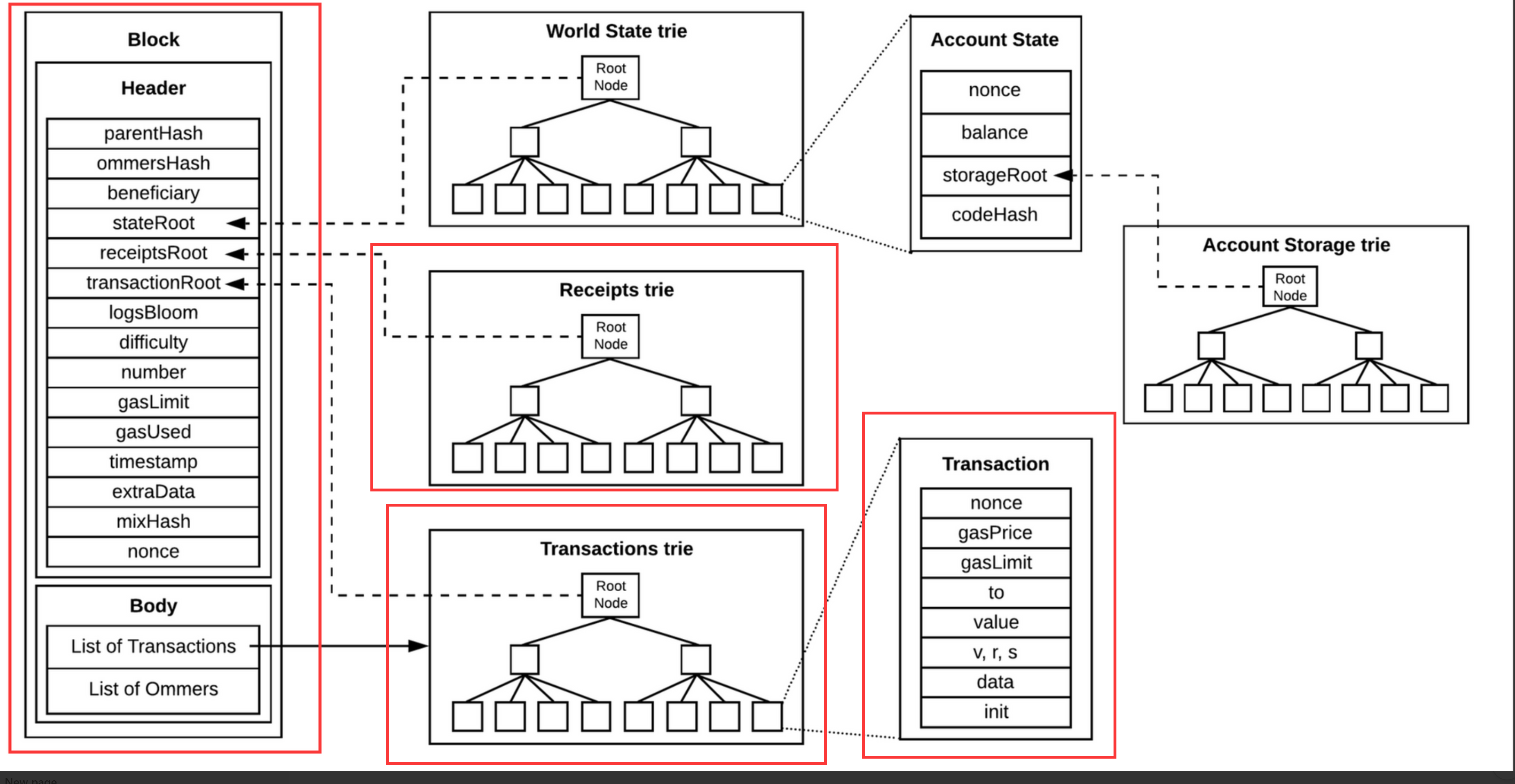
可以看到:
- 看到每个区块的信息
- 看到每笔交易的数据 (在开启了--txlookuplimit=0参数之后)
看不到:
- 外部、合约账户的状态信息,包括了:余额、账户noce、合约存储区,合约代码Hash
- 合约账户的代码

以上看不到的东西,来自于World State Trie始终无法完成构建。
足以可见,以太坊的运行性能严重受到LVDB、磁盘、存储的制约!
原因:
完全同步(Full Mode):
下载区块链的所有区块,并重播曾经发生过的所有交易。在执行此操作时,它存储事务的收据,同时不断更新世界状态树(World State Trie)
快速同步(Fast Mode)
不会重放所有交易,如果不使用SSD,我们能获得到的仍然只有红框的内容
而世界状态的trie树,是从全网节点上下载的,不是从0号区块一点点算出来的。
而即便如此,IO速度仍然是远远追不上 下载、出块的速度。
而世界状态树是所有树里面最庞大的树:
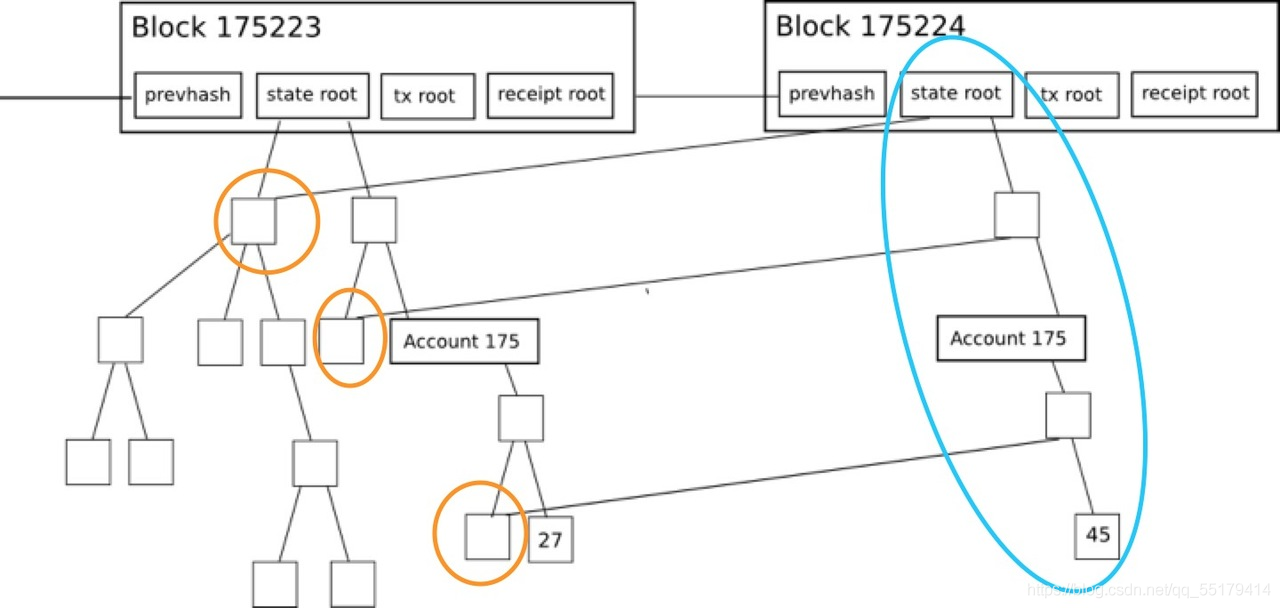
许多人错误地认为,因为它们有块,所以它们是同步的。 不幸的是,事实并非如此,因为没有执行任何交易,所以我们没有任何可用的账户状态(余额,随机数,智能合约代码和数据)。这些需要单独下载并与最新的块进行交叉检查。此阶段称为状态 trie 下载,它实际上与块下载同时运行;唉,现在比下载块需要更长的时间。
Trie是什么?在以太坊主网中,已经有大量帐户跟踪每个用户/合同的余额,nonce等。但是,帐户本身不足以运行节点,需要将它们链接到每个块上,以便节点实际上可以验证该帐户未篡改。该加密链接是通过在帐户上方创建树数据结构来完成的,每个级别将其下方的图层汇总到越来越小的层,直到到达单个根。这种包含所有帐户和中间密码证明的巨型数据结构称为状态Trie。
好的,为什么这会带来问题呢?这种TRIE数据结构是数亿个微型加密证明(Trie节点)的复杂链接。要真正拥有一个同步节点,您需要下载所有帐户数据,以及所有微小的加密证明,以验证网络中没有人试图欺骗您。这本身已经是疯狂的数据项。它变得更加混乱的部分是,此数据在不断变形:在每个块(15s)中,从此TRIE中删除了约1000个节点,并添加了约2000个新节点。这意味着您的节点需要同步每秒200次的数据集。最糟糕的是,当您同步时,网络正在向前发展,并声明您在下载时开始下载可能会消失,因此您的节点需要在尝试收集所有最新数据的同时不断关注网络。但是,除非您实际收集所有数据,否则您的本地节点无法使用,因为它无法在任何帐户上证明任何内容
总结:
- 世界状态树是不断地以极高速度在改变的,(每个块约会对树进行3000次操作)
- 状态同步主要受磁盘IO限制,而不是带宽限制。
- 以太坊中的状态trie包含数亿个节点,其中大多数节点采用单个散列的形式,最多引用16个其他散列。这是一种在磁盘上存储数据的可怕方式,因为磁盘中几乎没有结构,只有引用更多随机数的随机数。
- 不仅存储数据非常不理想,而且由于每秒200次的修改和对过去数据的修剪,我们甚至无法下载它。这是一种经过适当预处理的方法,可以使其导入速度更快,而不需要底层数据库对其进行过多的调整。最终的结果是,即使是现在的快速同步也会带来巨大的磁盘IO成本,这对于机械硬盘来说是太高了。
- 我们在下载世界状态Trie的同时,世界状态树正在以“超过”我们写入的速度发展。
- 由于使用的是HDD同步数据,直接导致我们永远不能完成世界状态树(World State Trie)的同步工作!