深入理解StateDB和快照机制
| Tags | 数据存储 |
|---|
什么是StateDB
众所周知,以太坊中状态机迁移的核心是:世界状态树(World State Trie)的改变。
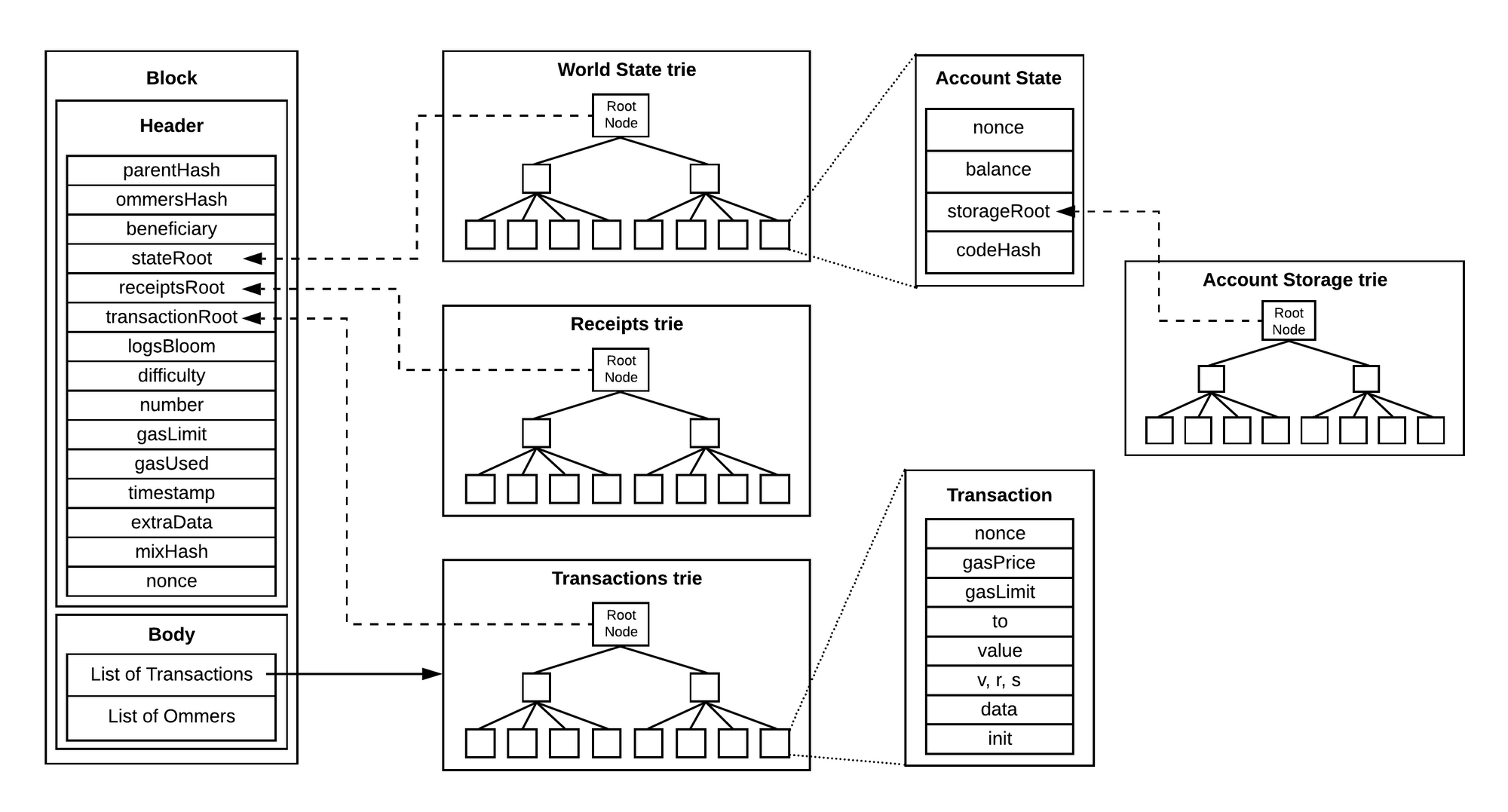
而随着以太坊中数据量的不断扩增,其世界树的深度和节点数也在疯狂膨胀,如果我们每次访问账户状态(EOA外部账户 或是 合约账户),都需要对世界状态树进行至少 N=树的深度 的访问,才能获取到账户的状态信息。
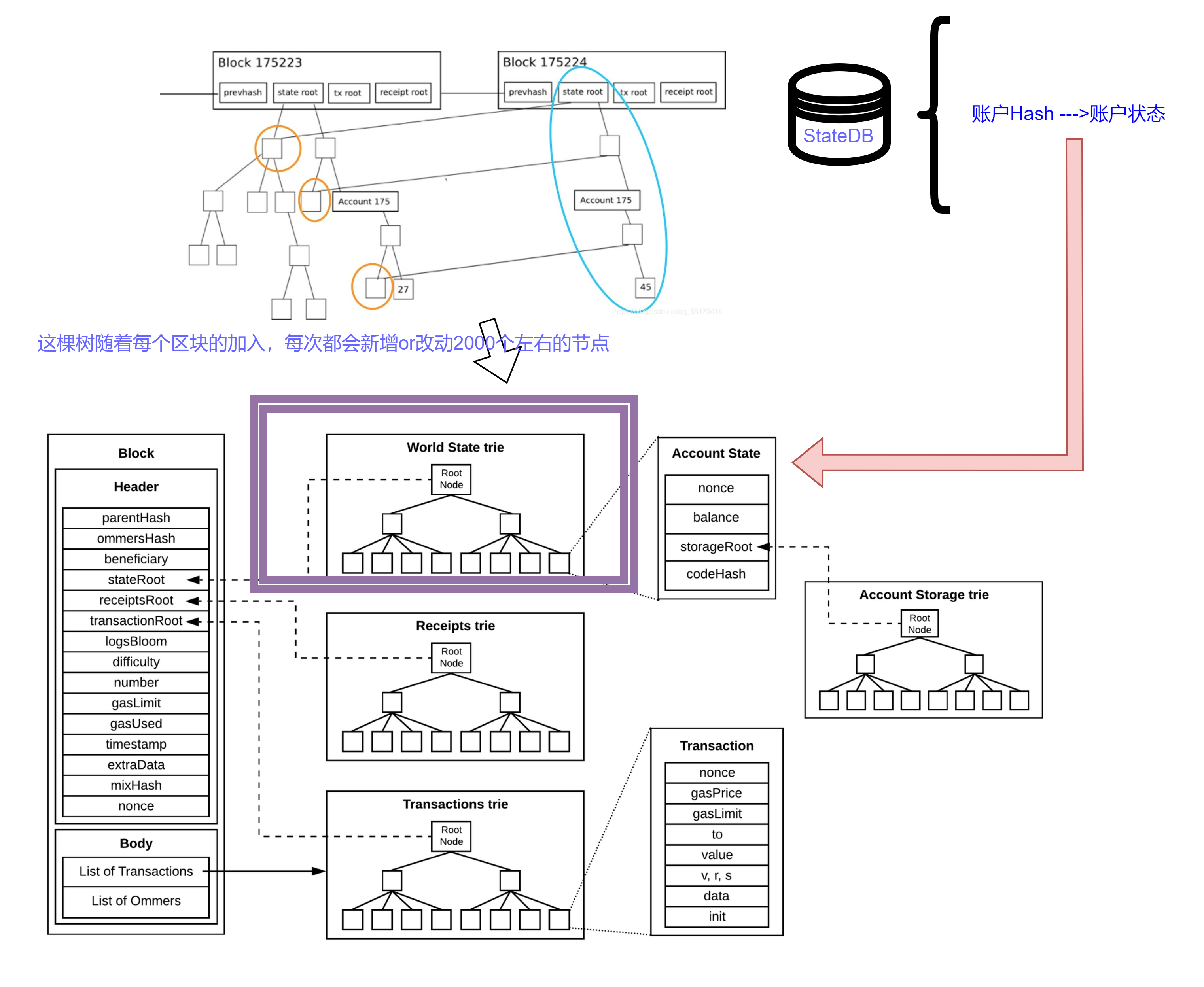
因此以太坊引入了一个类似缓存机制的状态DB,维护了一套账户状态到世界状态的映射
以太坊节点在几个不同的地方访问状态:
- 导入新块时,执行一系列的状态读取和写入。
- 当检索状态(例如合约调用,web3查询)时,EVM 仅执行读取
- 当节点正在同步,提供给其他P2P节点所同步。
特别的,对于智能合约来说,其特有的是一个账户存储树,
所有对 State 的修改,并不是直接修改底层数据库。而是暂时记录在内存中,只要在最终需要提交到数据库时,才从尝试 tryUpdate。
如果未改动,则从树中读取数据。 为了避免重复从树中读取,提高效率。所有获取过的数据,将会缓存在 map[common.Address*stateObject 中。
正是由于有了StateDB的存在,在我们读取数据的过程中,实际上存在着三个步骤:
- 尝试从内存的StateDB中取到已经缓存的数据
- 尝试从snapshots快照机制中获取
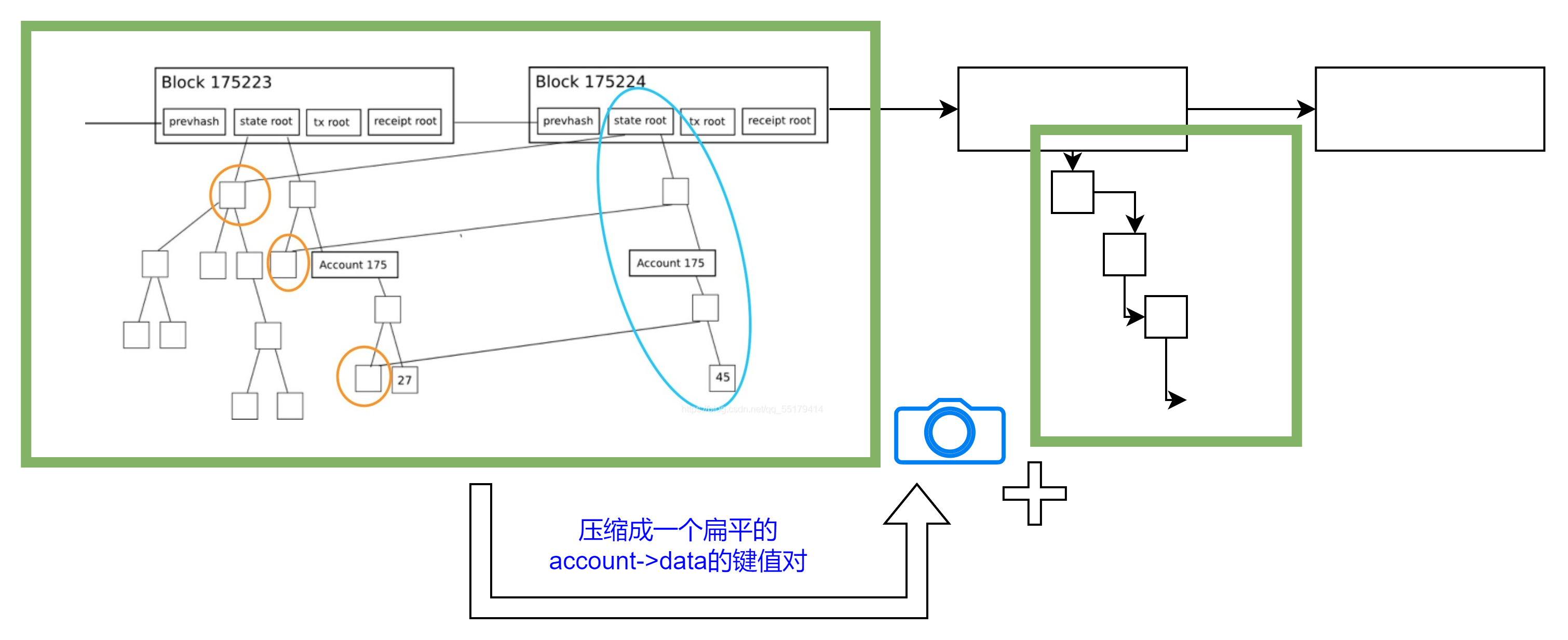
一个快照就是给定一个区块处的以太坊状态的完整视图。抽象掉实现方面的细节,它就是把所有账户和合约存储槽堆放在一起,都由扁平的键值对来表示。
每当我们想要访问某个账户或者某个存储槽的时候,我们只需付出一次 LevelDB 的查询操作即可,而不用在每棵树上查询 7~8 次。理论上来说,更新快照也很简单,处理完一个区块后,我们只需为每个要更新的存储槽多做 1 次额外的 LevelDB 写入操作即可。
当初始同步完成之后,参与主网的节点需要 9~10 小时来建构初始快照(此后再维持其可用性),还需要额外的 15 GB 以上的硬盘。
- 如果上面的都找不到,则从Trie树中依次去寻找。
- 大约2019年,Trie树的深度已经饱和了7。
- 这意味着,每个trie操作(例如读取余额,写入nonce)至少接触7-8个内部节点
- 因此将执行至少7-8个持久数据库访问。
- LevelDB还将其数据组织为最多7个级别,]最终结果是单次访问将放大为25-50 随机磁盘访问。
StateDB的生命周期
stateDB是用来管理世界状态的,准确的说是用来改变世界状态的。那么世界状态什么时候会改变呢?
1、打包交易进行挖矿的时候; 2、收到区块广播执行同步的时候;
也就是说,stateDB是从挖矿时从交易池取出交易并执行,然后打包等待挖矿,最后当区块挖矿成功后,将stateDB中的账户改变刷入数据库后,stateDB的使命就结束了,就可以从内存中删除。

总结:
- 以太坊的StateDB设计仅仅在同一个区块内实现了对世界状态的缓存。
- StateDB的存在仅仅只能让第2次及其之后的账户数据得到快速查询,第一次还是很慢!
- 以太坊出块时间在12 到14 秒之间,那么构建出的StateDB仅仅只能维护12-14秒的世界状态,一旦产生下一个区块,StateDB就会立刻清空。
- 因此不难看出,StateDB仍然未能解决IO性能带来的瓶颈,只是旨在对区块内的数据进行高速缓存之工作
- 快照机制解决了对账户和存储槽的缓存,只需进行1次LevelDB的访问+128个块的difference树的访问
- 牺牲:快照需要大约的额外磁盘开销主网中 20-25GB的空间
- 根据节点的负载,快照的构建需一周左右的时间